Thursday, January 14, 2016
Wednesday, June 25, 2014
CPU Cache Essentials
This post came to my mind after watching the excellent presentation of Scott Meyers called "CPU Caches and Why You care". This post will try to summarize the ideas of the presentation so if you have some spare time you can just watch the presentation on video.
To emphasize importance of cpu caches in our daily work we start with 2 examples:
The first problem is a simple traversing of 2 dimensional array. The way we can do this in c-like language is by traversing the array row by row. Alternatively we can traverse it column by column.
Strangely for large arrays (> 10MB) traversing column by column leads to terrible performance.
The second problem is a parallel processing of some data in large array. We divide the array into X chunks and process each chunk in a separate thread. For example we want to count number of bytes which are set to 1. The following implementation doesn't scale when we run it on machines with more and more cores.
This weird behavior can be explained after we learn about the cpu caches.
CPU caches are a small amount of unusually fast memory. We have 3 types of caches in a regular CPU:
For example L2 is 256KB chunk of fast memory (11 cycles access time) which is used to cache both data and instructions and which is shared by 2 hardware threads on single core.
 By the way there is one type of memory that we didn't mention which can beat the performance of all these layers - the cpu registers.
By the way there is one type of memory that we didn't mention which can beat the performance of all these layers - the cpu registers.
Now when we talk about making your programs fast and furious, the only thing that is really matters is how well you can fit into the cache hierarchy. It won't even matter if you are using machine with 64G. In the hardware world smaller is faster. Compact code and data structures will always be fastest.
Since access to main memory is so expensive, the hardware will bring a whole chunk of memory to put it into cache line. Typical size of cache line is 64 bytes so each time we read one byte of memory 64 bytes of data will enter our cache (and probably evict some other 64 bytes). Writing one byte of memory will eventually lead to writing 64 bytes of data to memory.
 One interesting thing about these cache lines is the fact that our hardware is pretty smart to perform prefetch of cache line once it detects forward/backward traversal.
One interesting thing about these cache lines is the fact that our hardware is pretty smart to perform prefetch of cache line once it detects forward/backward traversal.
Thinking back about first problem of traversing matrix. It is now clear why the column by column case is having such a bad performance. When we traversing column by column we are not using each cache line effectively. In fact be bring complete cache line just to access one byte and later when the cache line is evicted from the small cache we our accessing the second byte.
Reasoning about the coherency of the different caches becomes impossible task. Luckily we don't have to reason too much, the hardware will take care of synchronization as long as we will use proper synchronization primitives (high level mutexes, read/write barriers and etc). Unfortunately this simplification comes with cost - TIME. Your hardware will spend precious time on synchronization which will reduce the performance of your program.
 Another effect of CPU caches is called "False Sharing". Suppose core 0 reads address A and core 1 writes to address A+1. Since A and A+1 occupy same cache line, hardware will need to synchronize caches by constantly invalidating the cache line and catching it back. This is exactly what happens in problem 2 where:
Another effect of CPU caches is called "False Sharing". Suppose core 0 reads address A and core 1 writes to address A+1. Since A and A+1 occupy same cache line, hardware will need to synchronize caches by constantly invalidating the cache line and catching it back. This is exactly what happens in problem 2 where:
invalidates the cache line each increment.
Quick fix of using local variable to maintain result of each thread and setting them at the end leads to performance boost.
To conclude here are some tips you can use to boost performance by being aware of the CPU cache tradeoffs:
To emphasize importance of cpu caches in our daily work we start with 2 examples:
The first problem is a simple traversing of 2 dimensional array. The way we can do this in c-like language is by traversing the array row by row. Alternatively we can traverse it column by column.
uint64_t matrix[ROWS][COLUMNS]; uint64_t i,j; uint64_t ret; /* row by row */ for (i = 0; i < ROWS; i++) for (j = 0; j < COLUMNS; j++) ret += matrix[i][j]; /* column by column */ for (j = 0; j < COLUMNS; j++) for (i = 0; i < ROWS; i++) ret += matrix[i][j];
Strangely for large arrays (> 10MB) traversing column by column leads to terrible performance.
The second problem is a parallel processing of some data in large array. We divide the array into X chunks and process each chunk in a separate thread. For example we want to count number of bytes which are set to 1. The following implementation doesn't scale when we run it on machines with more and more cores.
char array[SIZE_10_MB]; int X = NUM_OF_CORES; int results[X]; void chunk_worker(int index) { int i; int work_size = SIZE_10_MB/X; for (i = work_size * index; i < work_size * (index + 1); i++) { if (array[i] == 1) { results[index] += 1; } } }
This weird behavior can be explained after we learn about the cpu caches.
CPU caches are a small amount of unusually fast memory. We have 3 types of caches in a regular CPU:
- D-cache - cache used to store data
- I-cache - cache used to store code (instructions)
- TLB - cache used to store virtual to real memory address translations
These caches are arranged in a typical 3 layer hierarchy:
typical i7-9xx (4 cores) example | | | share by | shared by | | | | I/D cache | cores | hw threads | latency | | L1 | 32KB/32KB | 1 | 2 | 4 cycles | | L2 | 256KB | 1 | 2 | 11 cycles | | L3 | 8MB | 4 | 8 | 39 cycles | | RAM | | | | 107 cycles |
For example L2 is 256KB chunk of fast memory (11 cycles access time) which is used to cache both data and instructions and which is shared by 2 hardware threads on single core.
By the way there is one type of memory that we didn't mention which can beat the performance of all these layers - the cpu registers.Now when we talk about making your programs fast and furious, the only thing that is really matters is how well you can fit into the cache hierarchy. It won't even matter if you are using machine with 64G. In the hardware world smaller is faster. Compact code and data structures will always be fastest.
Since access to main memory is so expensive, the hardware will bring a whole chunk of memory to put it into cache line. Typical size of cache line is 64 bytes so each time we read one byte of memory 64 bytes of data will enter our cache (and probably evict some other 64 bytes). Writing one byte of memory will eventually lead to writing 64 bytes of data to memory.
One interesting thing about these cache lines is the fact that our hardware is pretty smart to perform prefetch of cache line once it detects forward/backward traversal.Thinking back about first problem of traversing matrix. It is now clear why the column by column case is having such a bad performance. When we traversing column by column we are not using each cache line effectively. In fact be bring complete cache line just to access one byte and later when the cache line is evicted from the small cache we our accessing the second byte.
Reasoning about the coherency of the different caches becomes impossible task. Luckily we don't have to reason too much, the hardware will take care of synchronization as long as we will use proper synchronization primitives (high level mutexes, read/write barriers and etc). Unfortunately this simplification comes with cost - TIME. Your hardware will spend precious time on synchronization which will reduce the performance of your program.
Another effect of CPU caches is called "False Sharing". Suppose core 0 reads address A and core 1 writes to address A+1. Since A and A+1 occupy same cache line, hardware will need to synchronize caches by constantly invalidating the cache line and catching it back. This is exactly what happens in problem 2 where:results[index] += 1;
invalidates the cache line each increment.
Quick fix of using local variable to maintain result of each thread and setting them at the end leads to performance boost.
int array[SIZE_10_MB]; int X = NUM_OF_CORES; int results[X]; void chunk_worker(int index) { int i; int sum = 0; int work_size = SIZE_10_MB/X; for (i = work_size * index; i < work_size * (index + 1); i++) { if (array[i] == 1) { sum += 1; } } results[index] = sum; }
To conclude here are some tips you can use to boost performance by being aware of the CPU cache tradeoffs:
Data cache tips:
- Use linear array traversal. Hardware will often optimize and pref-etch the data so that the speedup will be substantial
- Use as much of cache line as possible. For example in the next code when else clause is happening, we are throwing complete cache line which was fetched by accessing the is_alive member. Solution to this could be to make sure that most objects are alive.
struct Obj { bool is_alive; ... }; std::vector<Object> objs; for (auto o: objs) { if (o.is_alive) do_stuff(o); else { // just thrown a cache line }
- Be alert for false sharing in multi-core systems
Code cache tips:
- Avoid iteration over heterogeneous sequence of objects with virtual calls. If we have sequence of heterogeneous objects the best thing would be to sort them by type so that executing virtual function of one object will lead to fetching code which can be used by the next object.
- Make fast paths using branch-free sequences of code
- Inline cautiously.
- Pros: reduce branches which will lead to speedup, compiler optimizations now possible
- Cons: code duplication reduces code cache use
- Use Profile-guided Optimizations (PGO) and Whole Program Optimizations (WPO) tools -these are automatic tools which will help you to optimize your code
Wednesday, February 12, 2014
Building Distributed Cache with GlusterFS - not a good idea
Cache is a popular concept. You can't survive in the cruel word of programming without using cache. Cache is inside you cpu. There is one inside you browser. Your favorite web site is serving pages from cache and you probably have one in your brain as well :)

Anyway, my mission was to build a distributed cache which can be used to speedup application X. This cache needed to be scalable and to allow extending it by adding more compute nodes. The compute nodes should be cheap amazon instances and the cache should provide very low latency (time until first byte of data arrives should be around 5ms).
Distributed file systems are a very cool peace of technology, so naturally it seems as a good idea to use it in building this cache. After reading about Ceph vs Gluster wars I've decided to settle down on Gluster. I liked very much the idea of translators which add functionality layer by layer. Each translator is a simple unit which handles one task of complicated file system.

The DHT translator in Gluster allows to distribute files between the different nodes. Later when the client wants to read file, it can locate the correct node using O(1) hash function computation and to read it directly from the node where it is located.
Using amazon, I quickly created 5 m1.large instances and installed glusterfs. The installation is pretty easy. I used my favorite tool for repeating tasks on multiple compute nodes (fabric) and after a while installation of x nodes became as simple as running
Next I created distributed glusterfs volume consisting of 5 nodes
I modified application X code to try and use the remote cache and my algorithm became something similar to:
And it worked well when there was small amount of application X instances (around 10). However when the amount of application X instances was increased (8 servers, 15 application X instances on each, total of 120 applications which continuously access glusterfs through fuse interface), I've noticed that access to mounted glusterfs file system became very slow.
Looking at latency of some of the glusterfs operation on client side (thanks good gluster has translator, called debug/io-stats, which can aggregate statistics), I've noticed that some of the lookup operation would take 10-20 seconds ! Basically lookup should be very lite operation, using the DHT translator the client should determine the exact server where the file should be located and then it can query it directly which will lead to distribution of stress between the 5 nodes. Each time I open the file a lookup command will be sent by gluster to determine where the file is located and later I can read it or write to it without a problem.
So why are lookups take so much time ? I realized I need to look at the network level. Luckily glusterfs has plugin for wireshark which can dissect traffic and show glusterfs operations.
Looking at the captured packets I saw that when we access file /file1/block1.bin, gluster will invoke 3 lookup operations. First for directory /, second for sub-directory file1 and then to file block1.bin.
Now here are the bad news: when performing lookup for directory, gluster will broadcast lookup request to all nodes and then wait until all nodes will respond. In my case one of the nodes (not the one where the actual file sits) would be super busy and would respond only after 5 seconds. And so the lookup request will wait for 5 seconds without trying to continue and actually communicate with the node where the file is located. This bad situation repeats for each path directory component and leads to awful performance with lookups.

Tweaking glusterfs options such as setting dht.lookup-unhashed=off, didn't help since this only relevant the file component and we still need to traverse at least two directory components until we reach the file component in the path.
So in my opinion such behavior makes gluster very unsuitable for functioning as cache where checking if data is in cache (lookup) is a frequent method. I guess hacking gluster and modifying the DHT translator can solve the issue (and introduce many other interesting issues :)
But this would be another interesting post ...
Anyway, my mission was to build a distributed cache which can be used to speedup application X. This cache needed to be scalable and to allow extending it by adding more compute nodes. The compute nodes should be cheap amazon instances and the cache should provide very low latency (time until first byte of data arrives should be around 5ms).
Distributed file systems are a very cool peace of technology, so naturally it seems as a good idea to use it in building this cache. After reading about Ceph vs Gluster wars I've decided to settle down on Gluster. I liked very much the idea of translators which add functionality layer by layer. Each translator is a simple unit which handles one task of complicated file system.
The DHT translator in Gluster allows to distribute files between the different nodes. Later when the client wants to read file, it can locate the correct node using O(1) hash function computation and to read it directly from the node where it is located.
Using amazon, I quickly created 5 m1.large instances and installed glusterfs. The installation is pretty easy. I used my favorite tool for repeating tasks on multiple compute nodes (fabric) and after a while installation of x nodes became as simple as running
>> fab -H hostname1,hostname2,hostnamexx -P -f gluster.py install_gluster create_volume create_mount
Next I created distributed glusterfs volume consisting of 5 nodes
>> gluster volume create cache hostname1:/brick1/cache hostname2:/brick1/cache hostname3:/brick1/cache hostname4:/brick1/cache hostname5:/brick1/cache
I modified application X code to try and use the remote cache and my algorithm became something similar to:
fd = open("/local_cache/file1/block1.bin", O_RDONLY); if (fd == -1) { fd = open("/gluster/file1/block1.bin", O_RDONLY); ... pread(fd, ....)
And it worked well when there was small amount of application X instances (around 10). However when the amount of application X instances was increased (8 servers, 15 application X instances on each, total of 120 applications which continuously access glusterfs through fuse interface), I've noticed that access to mounted glusterfs file system became very slow.
Looking at latency of some of the glusterfs operation on client side (thanks good gluster has translator, called debug/io-stats, which can aggregate statistics), I've noticed that some of the lookup operation would take 10-20 seconds ! Basically lookup should be very lite operation, using the DHT translator the client should determine the exact server where the file should be located and then it can query it directly which will lead to distribution of stress between the 5 nodes. Each time I open the file a lookup command will be sent by gluster to determine where the file is located and later I can read it or write to it without a problem.
Fop Call Count Avg-Latency Min-Latency Max-Latency --- ---------- ----------- ----------- ----------- STAT 58 2133.43 us 1.00 us 62789.00 us MKDIR 112 1009804.77 us 18.00 us 14452294.00 us OPEN 149 22108.78 us 2.00 us 1778858.00 us READ 151 160008.16 us 7.00 us 7246801.00 us FLUSH 149 13178.94 us 1.00 us 1594615.00 us SETXATTR 2633 232459.26 us 719.00 us 10749344.00 us LOOKUP 4725 641604.43 us 2.00 us 17630043.00 us FORGET 1 0 us 0 us 0 us RELEASE 149 0 us 0 us 0 us ------ ----- ----- ----- ----- ----- --- ----- ----- ----- ---
So why are lookups take so much time ? I realized I need to look at the network level. Luckily glusterfs has plugin for wireshark which can dissect traffic and show glusterfs operations.
Looking at the captured packets I saw that when we access file /file1/block1.bin, gluster will invoke 3 lookup operations. First for directory /, second for sub-directory file1 and then to file block1.bin.
Now here are the bad news: when performing lookup for directory, gluster will broadcast lookup request to all nodes and then wait until all nodes will respond. In my case one of the nodes (not the one where the actual file sits) would be super busy and would respond only after 5 seconds. And so the lookup request will wait for 5 seconds without trying to continue and actually communicate with the node where the file is located. This bad situation repeats for each path directory component and leads to awful performance with lookups.
Tweaking glusterfs options such as setting dht.lookup-unhashed=off, didn't help since this only relevant the file component and we still need to traverse at least two directory components until we reach the file component in the path.
So in my opinion such behavior makes gluster very unsuitable for functioning as cache where checking if data is in cache (lookup) is a frequent method. I guess hacking gluster and modifying the DHT translator can solve the issue (and introduce many other interesting issues :)
But this would be another interesting post ...
Monday, June 10, 2013
Coroutines for the greater good
Functions are the basic blocks of our daily code. This mechanism provides extremely simple and powerful abstraction. We use the stack memory as our main work space, storing there local variables and the return address. When the function returns, it pops the return address from the stack and jumps to it, allowing to continue previous function execution.
Once the function returns all it's internal state (local variables) is destroyed and on next invocation of the function we basically need to start from scratch. We can overcome this situation by using some clever techniques but there is a better solution.
Coroutines allow us to return from function by preserving the current context. Such coroutine can yield by passing the execution to other function which may decide to call the original function again. When this happens the execution will resume from the point of yield.
Simple example for coroutines is the consumer-producer pattern. This use case can be implemented in the following way using coroutines:
One example of interesting usage for coroutines appears in the qemu project. Qemu is the workhorse of virtualization infrastructure and it is used extensively to provide devices emulation for hypervisors such as kvm and xen.
On Jan 2011 coroutines were introduced into the qemu code base. The authors wanted to use the coroutines power to overcome some of the complexity involved in handling asynchronous calls. Before coroutines, many operations that could block were performed in asynchronous way using callbacks. This lead to complicated code since chunks of code were separated into single steps each implemented as separate callback. Temporary structures were used to pass parameters to callbacks and the whole picture looked complicated and unreadable.
With introduction of coroutines, simple interface was established to invoke cooperative functions:
There are several implementations to the coroutines semantics inside the qemu:
Once the function returns all it's internal state (local variables) is destroyed and on next invocation of the function we basically need to start from scratch. We can overcome this situation by using some clever techniques but there is a better solution.
Coroutines allow us to return from function by preserving the current context. Such coroutine can yield by passing the execution to other function which may decide to call the original function again. When this happens the execution will resume from the point of yield.
Simple example for coroutines is the consumer-producer pattern. This use case can be implemented in the following way using coroutines:
void coroutiine__ producer() { while (!queue_is_full(q)) { item_t *item = new_item(); queue_insert(q, item); } coroutine_yield(consumer); } void coroutiine__ consumer() { while (!queue_is_empty(q)) { item_t *item = queue_remove(q); consume_item(item); } coroutine_yield(producer); }
One example of interesting usage for coroutines appears in the qemu project. Qemu is the workhorse of virtualization infrastructure and it is used extensively to provide devices emulation for hypervisors such as kvm and xen.
On Jan 2011 coroutines were introduced into the qemu code base. The authors wanted to use the coroutines power to overcome some of the complexity involved in handling asynchronous calls. Before coroutines, many operations that could block were performed in asynchronous way using callbacks. This lead to complicated code since chunks of code were separated into single steps each implemented as separate callback. Temporary structures were used to pass parameters to callbacks and the whole picture looked complicated and unreadable.
With introduction of coroutines, simple interface was established to invoke cooperative functions:
/* Creating and starting a coroutine is easy: */ coroutine = qemu_coroutine_create(my_coroutine); qemu_coroutine_enter(coroutine, my_data); /* The coroutine then executes until it returns or yields: */ void coroutine_fn my_coroutine(void *opaque) { my_data_t *my_data = opaque; /* do some work */ qemu_coroutine_yield(); /* do some more work */ }
There are several implementations to the coroutines semantics inside the qemu:
- coroutine-ucontext.c - implements coroutines using swapcontext system call and the sigsetjmp/siglongjmp calls. The former creates and switches to new stack and the later calls used to jump from one context to other.
- coroutine-gthread.c - uses glib threads to create abstraction of coroutines. The actual switch between coroutines stops the current thread and activates next thread which executes the cooperative task.
- coroutine-win32.c - Is the implementation on windows. Windows allows to implement coroutines easily using fibres system calls.
- coroutine-sigaltstack.c - Unlike in the ucontext implementation, here sigaltstack system call is used to switch stack and create context which is later accessed using sigsetjmp/siglongjmp
Different programming languages have different implementations to the coroutines abstraction. One of the best resources on the coroutines in python, is the "A Curious Course on Coroutines and Concurrency" tutorial.
Saturday, December 1, 2012
Using performance counters on linux
One extremely useful feature linux has to offer is the ability to profile your system (user space and kernel) using the perf utility.
In a nutshell this utility allows you to count hardware and software events in linux kernel. Additional bonus is that when you count these events you can record cpu instruction pointer at the time of the event. Instruction pointer records, later can be used to generate concise execution profile of the kernel/user space code.
Similarly to git, perf uses sub-utils to introduce various functionality:
The first step is to list available events:
There are tons of events which we can divide into the following main categories:
filtering using -e flag is possible and it is possible to count events on existing process using -p flag
Another step in using perf is to realize that events can be recorded using record command:
And later code execution profile can be created using report command (each time event occur the current instruction pointer is recorded as well):
We can filter the kernel code and see where in our program we spend most of our time
Also by default we use cpu-clock event as the point where we stop to look at our code execution. We can use different events to find out interesting things. For example what are the places in our code that cause page faults:
To conclude, perf utility is extremely powerful tool. It provides accurate statistics with very little overhead, doesn't require recompilation and can be used to completely understand the overheads of kernel modules and user space application.
What a nice addition to the arsenal of your favorite hacking tools :)
In a nutshell this utility allows you to count hardware and software events in linux kernel. Additional bonus is that when you count these events you can record cpu instruction pointer at the time of the event. Instruction pointer records, later can be used to generate concise execution profile of the kernel/user space code.
Similarly to git, perf uses sub-utils to introduce various functionality:
The first step is to list available events:
root@dev-12:# perf list List of pre-defined events (to be used in -e): cpu-cycles OR cycles [Hardware event] stalled-cycles-frontend OR idle-cycles-frontend [Hardware event] stalled-cycles-backend OR idle-cycles-backend [Hardware event] instructions [Hardware event] cache-references [Hardware event] cache-misses [Hardware event] branch-instructions OR branches [Hardware event] branch-misses [Hardware event] bus-cycles [Hardware event] cpu-clock [Software event] task-clock [Software event] page-faults OR faults [Software event]
There are tons of events which we can divide into the following main categories:
- Hardware events
- Hardware cache events
- Software events
- Tracepoint events
Tracepoints events are special places in kernel that were specified by developers as a good position to trace. Stopping there usually brings you to the location where some important kernel functions starts or completes.
For example block:block_rq_complete trace event is passed when block i/o request completes.
Hardware events make use of special cpu hardware registers, which count cpu cpecific hardware events and trigger interrupt when certain threshold is passed. Software events do not require special hardware support and usually generated by kernel handlers which process special events such as page fault.
To watch statistics of events in the system you can use stat command:
root@dev-12:# perf stat -e syscalls:sys_enter_write,page-faults \
echo hello world > 1.txt Performance counter stats for 'echo hello world': 1 syscalls:sys_enter_write 165 page-faults 0.001013974 seconds time elapsed
filtering using -e flag is possible and it is possible to count events on existing process using -p flag
Another step in using perf is to realize that events can be recorded using record command:
root@dev-12:# perf record -f hdparm -t /dev/vda > /dev/null [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.038 MB perf.data (~1673 samples) ]
And later code execution profile can be created using report command (each time event occur the current instruction pointer is recorded as well):
root@dev-12:/home/local/a/hdparm-9.37# perf report # Events: 1K cpu-clock # # Overhead Command Shared Object Symbol # ........ ....... ................. .................................... # 25.80% hdparm [kernel.kallsyms] [k] copy_user_generic_string 8.21% hdparm [kernel.kallsyms] [k] blk_flush_plug_list 4.69% hdparm [kernel.kallsyms] [k] get_page_from_freelist 3.62% hdparm [kernel.kallsyms] [k] add_to_page_cache_locked 3.09% hdparm hdparm [.] read_big_block 2.77% hdparm [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore 2.51% hdparm [kernel.kallsyms] [k] kmem_cache_alloc 1.87% hdparm [kernel.kallsyms] [k] __mem_cgroup_commit_charge 1.76% hdparm [kernel.kallsyms] [k] file_read_actor 1.76% hdparm [kernel.kallsyms] [k] __alloc_pages_nodemask 1.55% hdparm [kernel.kallsyms] [k] alloc_pages_current
We can filter the kernel code and see where in our program we spend most of our time
root@dev-12:# perf report -d hdparm # # Events: 64 cpu-clock # # Overhead Command Symbol # ........ ....... .............. # 90.62% hdparm read_big_block 9.38% hdparm time_device
Also by default we use cpu-clock event as the point where we stop to look at our code execution. We can use different events to find out interesting things. For example what are the places in our code that cause page faults:
root@dev-12:# perf record -f -e page-faults -F 100000 hdparm -t /dev/vda > /dev/null [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.006 MB perf.data (~278 samples) ] root@dev-12:# perf report # # Events: 87 page-faults # # Overhead Command Shared Object Symbol # ........ ....... ................. ........................ # 72.05% hdparm hdparm [.] prepare_timing_buf 10.96% hdparm ld-2.15.so [.] 0x16b0 5.34% hdparm libc-2.15.so [.] 0x86fc0 2.53% hdparm [kernel.kallsyms] [k] copy_user_generic_string 1.26% hdparm libc-2.15.so [.] __ctype_init 1.26% hdparm libc-2.15.so [.] _IO_vfscanf 1.26% hdparm libc-2.15.so [.] strchrnul 1.26% hdparm libc-2.15.so [.] mmap64 1.26% hdparm hdparm [.] main 1.26% hdparm hdparm [.] get_dev_geometry 1.26% hdparm [kernel.kallsyms] [k] __strncpy_from_user 0.28% hdparm [kernel.kallsyms] [k] __clear_user
To conclude, perf utility is extremely powerful tool. It provides accurate statistics with very little overhead, doesn't require recompilation and can be used to completely understand the overheads of kernel modules and user space application.
What a nice addition to the arsenal of your favorite hacking tools :)
Saturday, November 24, 2012
Software Craftsmanship vs Hackers
Recently it came to my mind that there are two prime schools of programmers in the world. These two groups have opposite values and possess orthogonal skills.
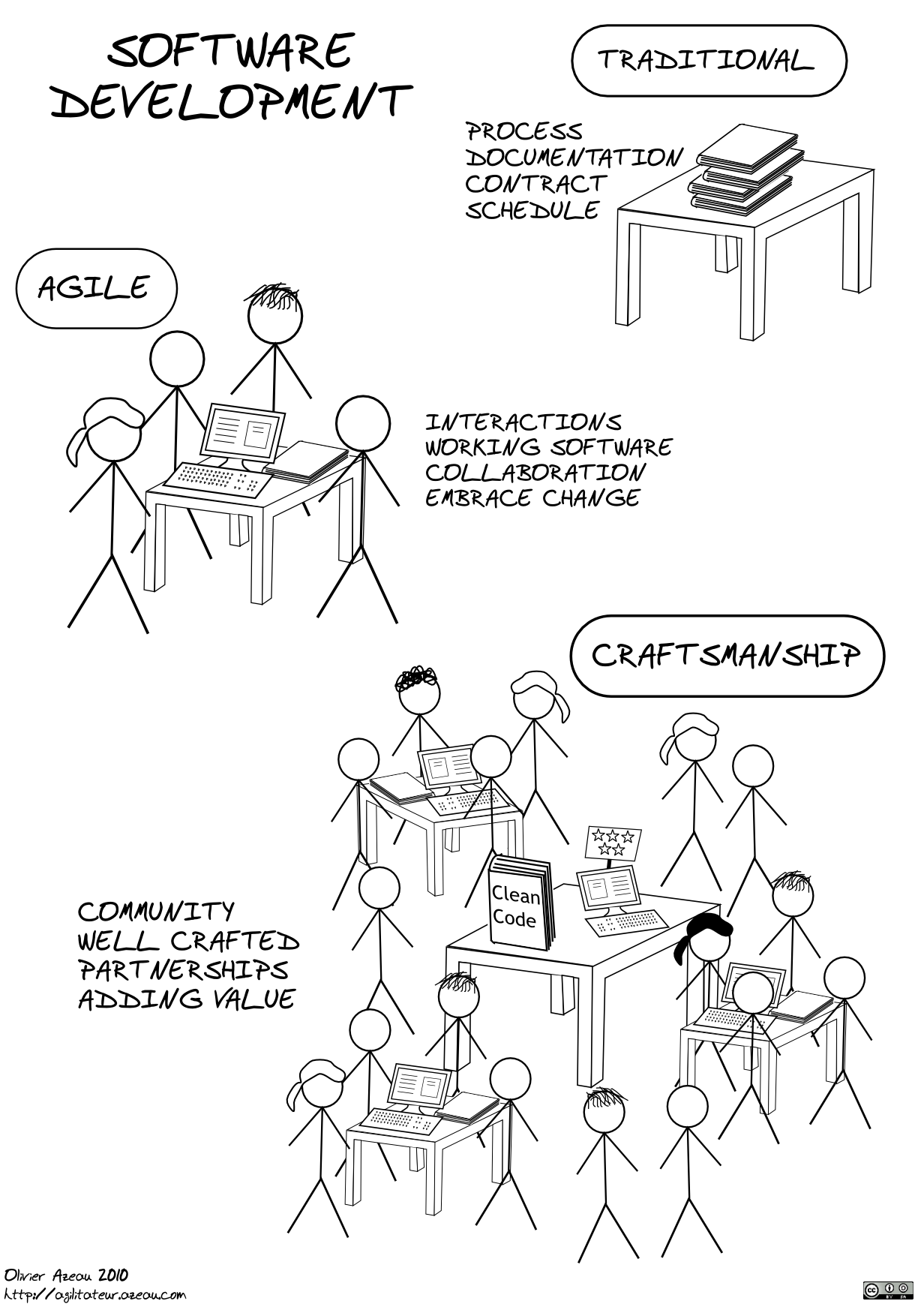
The first group called "Software craftsmanship" is focused on the art of writing beautiful and flexible code. Talented people, who belong to this group, build beautiful software designs, practice TDD/BDD and re-factor their code until the last code-smell disappears. The role models for this group are people like uncle bob and they all have read pragmatic programmer and clean code books.

The other group is what we call "hackers". Not only in the sense of people practicing computer security and reverse engineering but also in the broader sense of people who have low level orientation, can quickly understand how closed system is working and modify it to server their purposes. These extraordinary people can write truly amazing software in short period of time and use one line of perl to destroy somebody's world (try the next perl peace of code if you feel lucky) .
Now if you ask your fellow "hacker" to design production system there is high probability that you will get your system soon enough written in ASSEMBLY :). Or you will get it in your favorite c++ without classes, inheritance, templates, stl and all this fancy stuff real hackers never use. And god forbid no unit testing or comments in code because it is written in plain c++ or c or whatever... And you should know how to read code! And it works! Unless there is bug which you can fix in 1 sec :)
If you ask your enlightened friend from the "Software craftsmanship" group to find out why your mouse stops working whenever you send UDP packet to port 666. There is big chance that you will find him after 10 hours of googling and sending mails to vendors and support teams all around the world, telling you that you mouse is stupid and there is no real service on port 666 and that there is no problem with port 667 so who cares ...
So what should you do ? Whom should you join ? As with everything in the world there is no black and white only. In my opinion a good programmer should have a balance of the two types of skills. Don't compromise on the quality of your code and don't afraid of low level stuff. Create quick prototypes when you need but remember that later real people will have to read and maintain your code. And most important remember that it is better to be healthy and rich then poor and sick (or just poor or just sick).

The first group called "Software craftsmanship" is focused on the art of writing beautiful and flexible code. Talented people, who belong to this group, build beautiful software designs, practice TDD/BDD and re-factor their code until the last code-smell disappears. The role models for this group are people like uncle bob and they all have read pragmatic programmer and clean code books.

{kind=link}
The other group is what we call "hackers". Not only in the sense of people practicing computer security and reverse engineering but also in the broader sense of people who have low level orientation, can quickly understand how closed system is working and modify it to server their purposes. These extraordinary people can write truly amazing software in short period of time and use one line of perl to destroy somebody's world (try the next perl peace of code if you feel lucky) .
1 2 3 4 5 6 | # /usr/bin/env perl # Danger !!! This script can kill your root file system $? ? s:;s:s;;$?: : s;;=]=>%-{<-|}<&|`{; ; y; -/:-@[-`{-};`-{/" -; ; s;;$_;see |
Now if you ask your fellow "hacker" to design production system there is high probability that you will get your system soon enough written in ASSEMBLY :). Or you will get it in your favorite c++ without classes, inheritance, templates, stl and all this fancy stuff real hackers never use. And god forbid no unit testing or comments in code because it is written in plain c++ or c or whatever... And you should know how to read code! And it works! Unless there is bug which you can fix in 1 sec :)
If you ask your enlightened friend from the "Software craftsmanship" group to find out why your mouse stops working whenever you send UDP packet to port 666. There is big chance that you will find him after 10 hours of googling and sending mails to vendors and support teams all around the world, telling you that you mouse is stupid and there is no real service on port 666 and that there is no problem with port 667 so who cares ...
So what should you do ? Whom should you join ? As with everything in the world there is no black and white only. In my opinion a good programmer should have a balance of the two types of skills. Don't compromise on the quality of your code and don't afraid of low level stuff. Create quick prototypes when you need but remember that later real people will have to read and maintain your code. And most important remember that it is better to be healthy and rich then poor and sick (or just poor or just sick).

{kind=link}
Friday, November 9, 2012
Another one bites the blog
So after many many years of not doing what the rest of the world is doing (eating hamburgers ? ), I finally decided to join the community and start my own technical blog.
In this blog I hope to focus on some of the interesting stuff I enjoy in my profession: low level programming, kernel, storage, virtualization and functional programming.
The name of the blog: meta-x86 is a merge of two things: the shortcut in my favorite editor (meta+x) and the architecture I enjoy hacking.
Get ready for quality posts :)
In this blog I hope to focus on some of the interesting stuff I enjoy in my profession: low level programming, kernel, storage, virtualization and functional programming.
The name of the blog: meta-x86 is a merge of two things: the shortcut in my favorite editor (meta+x) and the architecture I enjoy hacking.
Get ready for quality posts :)